• L’incertitude sur une mesure x peut être exprimée par :
◊
l’incertitude absolue
(dont l’unité est compatible avec
) ;
◊
l’incertitude relative
(proportion, sans unité).
• L’incertitude de mesure peut être :
◊
systématique : pour une série de mesures avec un même appareil
déréglé, toutes les mesures sont décalées de façon analogue ;
◊
aléatoire : pour une série de mesures d’une même quantité avec des
appareils différents, déréglés de façon aléatoire, alors la série
des résultats a des “fluctuations” aléatoires autour d’une valeur
moyenne non décalée.
• Les incertitudes systématiques (parfois nommées “erreurs”) ne peuvent être réduites qu’en comprenant leur origine et en les corrigeant (par modification des appareils ou par calcul).
Les incertitudes aléatoires peuvent être réduites par des
méthodes statistiques : en calculant la moyenne sur un grand
nombre de mesures.
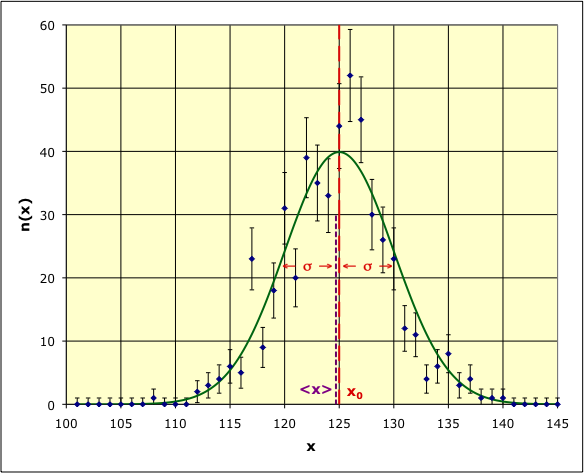
• Pour une série de mesures d’une même longueur à l’aide de règles graduées de précision médiocre (), on trace l’histogramme du nombre de fois où la mesure a donné le résultat .
• Pour une grandeur dont la mesure n’a que des incertitudes aléatoires, la probabilité de trouver une valeur en mesurant suit souvent la loi de Gauss : où la constante est telle que , ce qui correspond à : .
On obtient une répartition “en cloche”, centrée en une valeur
proche de .
La “demi-largeur à mi-hauteur” est de l'ordre de
“l’écart-type” et
correspondant à l’ordre de grandeur de la précision des mesures.
◊ remarque : une incertitude
est superposée à chaque point de l’histogramme pour visualiser
l’effet des fluctuations statistiques ; on voit ainsi que la
“courbe de Gauss” est comparable à l’histogramme.
• Pour assez
grand (
est très grand pour l’étude d’une longueur), la valeur moyenne
:
est une bonne approximation de
(l’écart constaté est compatible avec l’incertitude).
• Les calculatrices permettent généralement le calcul de l'écart
type (ou de la “variance” :
; on obtient ainsi :
.
L’incertitude statistique sur la moyenne est alors estimée par
:
.
☞ remarque : l’incertitude ne tend pas vers zéro pour un nombre
infini de mesures, car il subsiste généralement des incertitudes
systématiques.
• L’incertitude statistique n'est pas une limite infranchissable
mais simplement “assez probable” ; ainsi pour une loi de
répartition gaussienne :
◊
probabilité
d’obtenir un écart
;
◊
probabilité
d’avoir
;
◊
probabilité
de trouver
...
◊ remarque : ceci suppose que l'écart type est connu par étude
statistique d'au moins vingt mesures ; s'il est seulement estimé
d'après de petits échantillons, la répartition suit plutôt la loi
de Student.
◊ remarque : si pour des raisons de marges de sécurité, on
utilise une incertitude à
,
il faut bien l'indiquer pour “propager” correctement son effet sur
les calculs utilisant la mesure concernée.
• Les notices des instruments de mesure doivent normalement
indiquer une estimation des incertitudes de mesures (d'après des
statistiques effectuées par le fabricant).
Elles sont généralement présentées sous la forme d'un
pourcentage plus une constante. Par exemple : “”
signifie qu'une mesure de tension
correspond à
.
• Dans le cas d’une grandeur définie par
,
l’incertitude peut être
estimée par :
; toutefois, cette façon de calculer est parfois trop
pessimiste (incertitude surestimée).
• Si les incertitudes sont essentiellement aléatoires, elles
sont estimées par :
afin de prendre en compte les corrélations éventuelles entre et
.
Un estimateur de la covariance est
; le coefficient de corrélation est tel que
.
Quand on ignore s'il y a des corrélations, on peut faire comme
s'il n'y en avait pas, mais cela conduit dans quelques cas à des
résultats déraisonnables.
• Ainsi par exemple pour un produit
de deux variables indépendantes, on combine les incertitudes
relatives : .
Par contre pour
;
; la relation simplifiée donne :
alors que le résultat corrélé est
(ce qui correspond d'ailleurs dans ce cas à l'approximation
pessimiste).
![]() exercices
n° I, II et III.
exercices
n° I, II et III.
• Lors de l'exploitation des données expérimentales, on est
souvent amené à ajuster un modèle théorique pour représenter un
ensemble de mesures. Il est alors généralement plus simple, quand
c'est possible, de se ramener à des notations telles que le modèle
soit affine.
Bien que des méthodes statistiques rigoureuses existent pour
estimer les incertitudes sur les coefficients du modèle à partir
de l'ensemble des données, une estimation empirique rapide est
très souvent suffisante à ce niveau.
• Ainsi, pour une série de mesures représentées par une droite,
on commence par vérifier que cette représentation est acceptable
(compte tenu des incertitudes sur les points) :
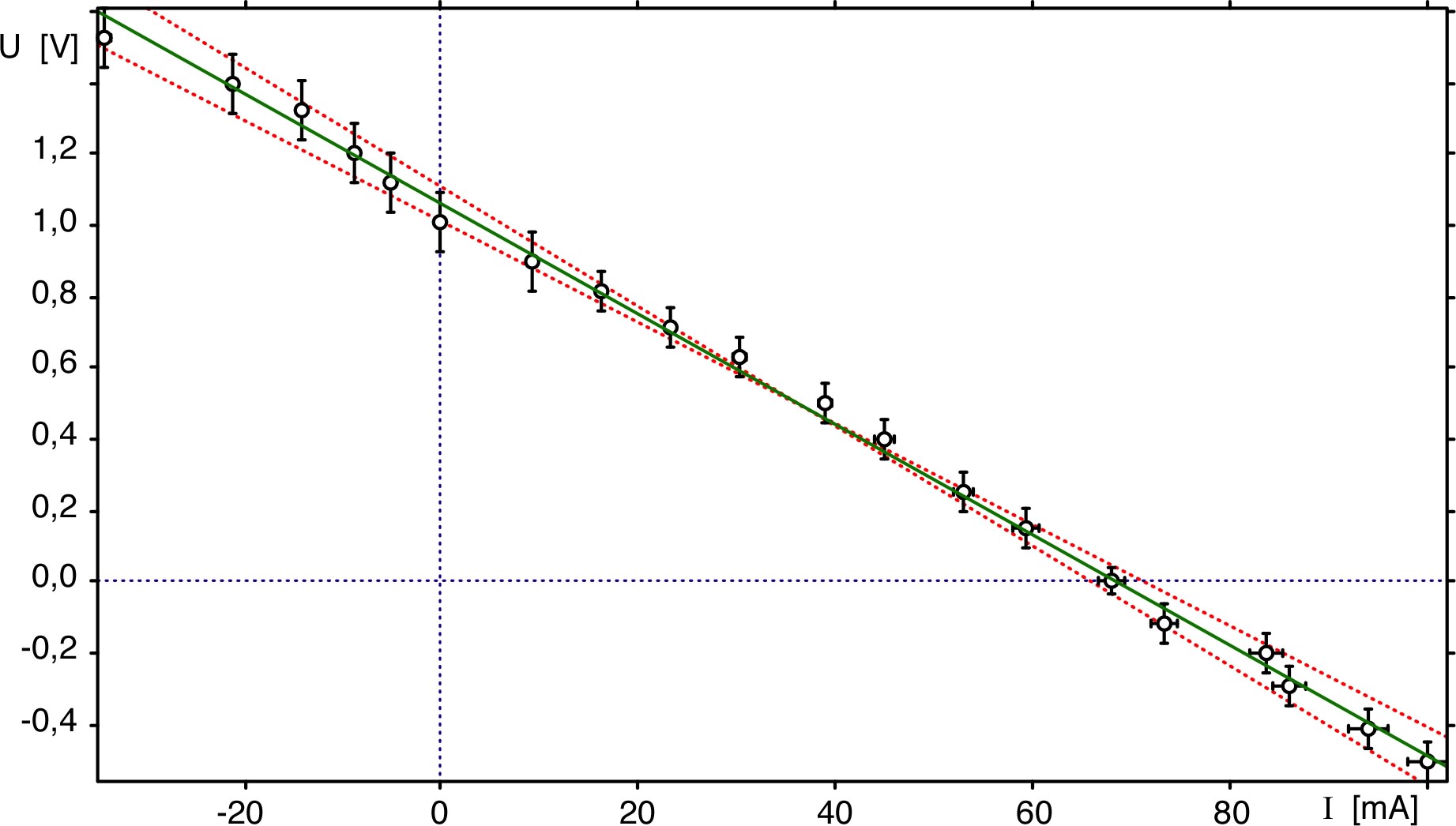
L'incertitude sur la pente ()
peut être estimée d'après les incertitudes sur les points,
divisées par le facteur statistique lié au nombre de points
: .
◊ remarque : un logiciel spécialisé calcule plus
précisément
.
◊ remarque : si on ajuste le modèle
, on constate ici la corrélation positive entre les
paramètres et : pour que
la droite passe “au mieux” par l'ensemble des points, une
surestimation de est
associée à une surestimation de (et
inversement).
◊ remarque : si ce type de démarche est appliquée de façon
raisonnée, on peut vérifier que l'ajustement du modèle
donne le même résultat pour les paramètres et
.
• Il existe des circonstances où les fluctuations de part et
d'autre du modèle ne sont que très médiocrement compatibles avec
l'estimation des incertitudes.
Si, après vérification de l'absence de biais évident, on juge
que le modèle est tout de même acceptable mais que les
incertitudes ont été sous-estimées, on peut proposer de les
multiplier par un “facteur d'échelle” tel que la compatibilité
soit plausible.
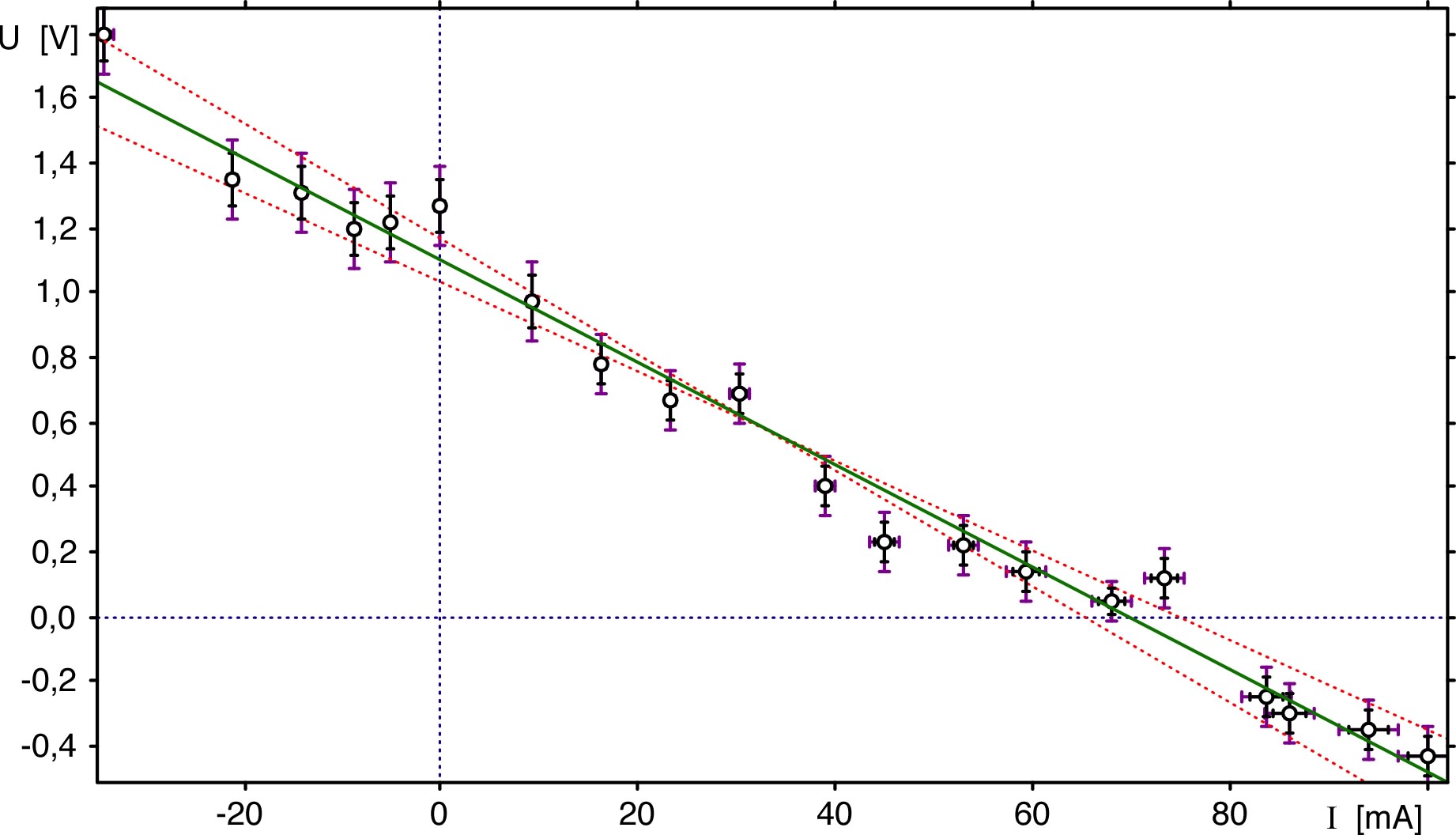
Pour cet exemple, un facteur d'échelle de l'ordre de semble
raisonnable ; on obtient ainsi
.